Abacum
From JSON editor to self-serve data layer
Overview
At Abacum, finance teams moved from relying on implementation support for every integration to being able to configure and manage their own data layer.
This reduced dependency on internal teams, sped up onboarding, and gave users direct control over datasets, transformations, and column configuration for the first time.
The starting point was a back-office JSON editor with no real interface between the data and the user. The work focused on introducing that missing layer, making it usable for FP&A teams without losing the flexibility the system already had.
Context
My role
The integrations and datasets squad had been running without a dedicated designer. Customer autonomy had become a higher priority, and the squad needed someone focused on it full time.
When I joined, the problem was clear and some directions had been explored but not a solution yet. I took ownership of the design work from that point: continued the exploration, tested directions with the customer support team and directly with customers, and pushed the work toward something shippable.
Being the first dedicated designer on the squad also meant building how design worked within that team from scratch: the relationships with engineering and the PM, how we tested and validated, how we handled tradeoffs between flexibility and usability.
The problem
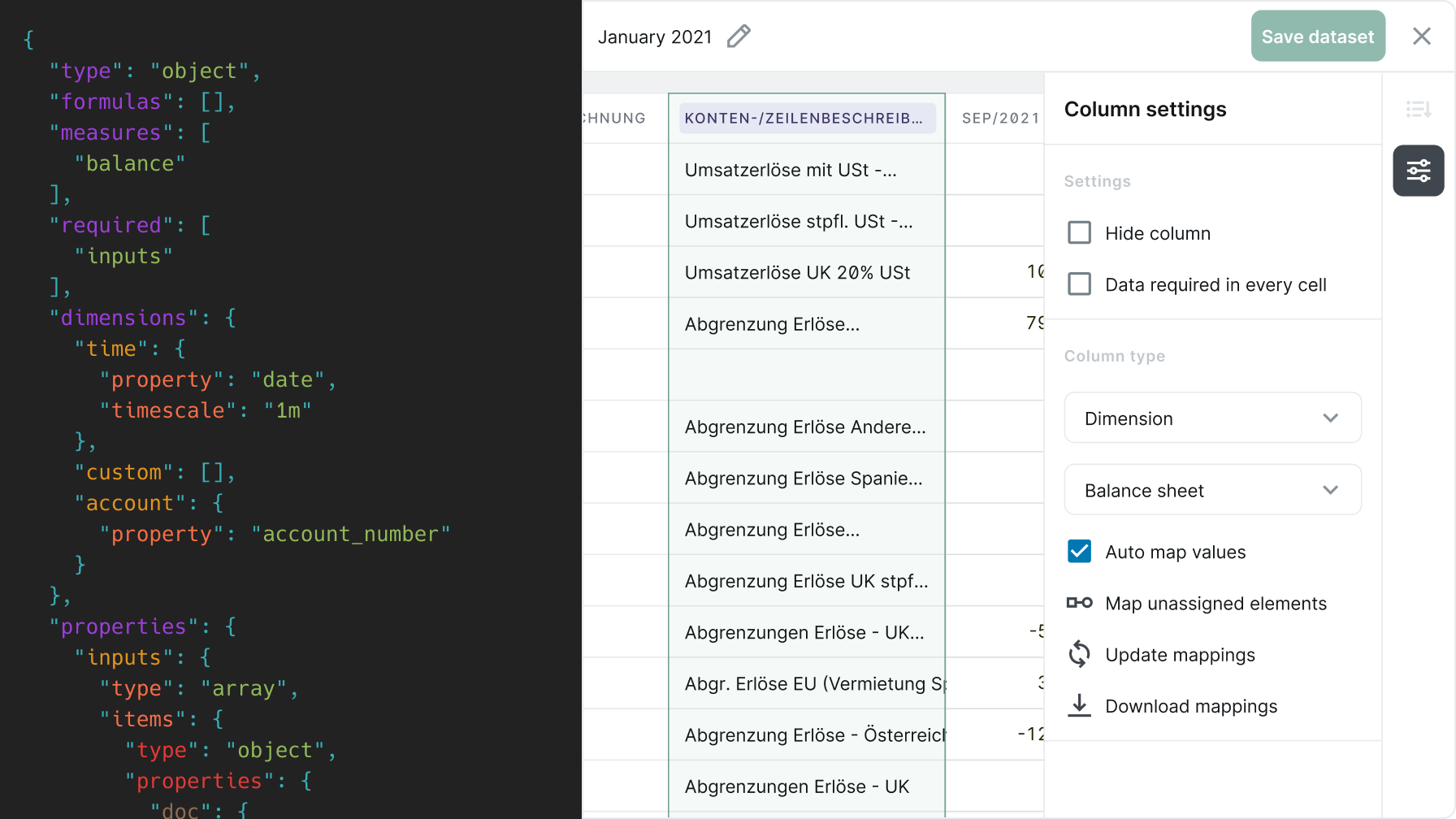
Finance teams couldn't own their own data
When I joined, working with data meant editing JSON directly. There was no UI to guide users or abstract the underlying structure, and the implementation team had to step in every time something changed.
But early explorations had already started, and I ran a first round of user tests to understand where the real friction was. Three customers walked through the flows. What came back was more nuanced than "the UI is confusing."
The core issue was a language mismatch. Users expected to work with dimensions, mappings, and date formats but the interface was giving them data types and schema configuration. For an FP&A team the difference between something that feels like their tool and something that feels like a developer's tool they've been handed matters.
The most experienced user in the tests, someone who had been working with the product the longest, went further than surface feedback. He flagged transformation restrictions based on dataset dependencies, the need for validation when creating dimension names, and uncertainty about what happened to data after mapping. He was thinking about what would break at scale.
That shaped how I prioritised. The problem went deeper than missing UI: the system was exposed at the wrong level of abstraction, and users had no way to reason about what was happening to their data or trust that it was correct.
Approach
Evolving the system without breaking it
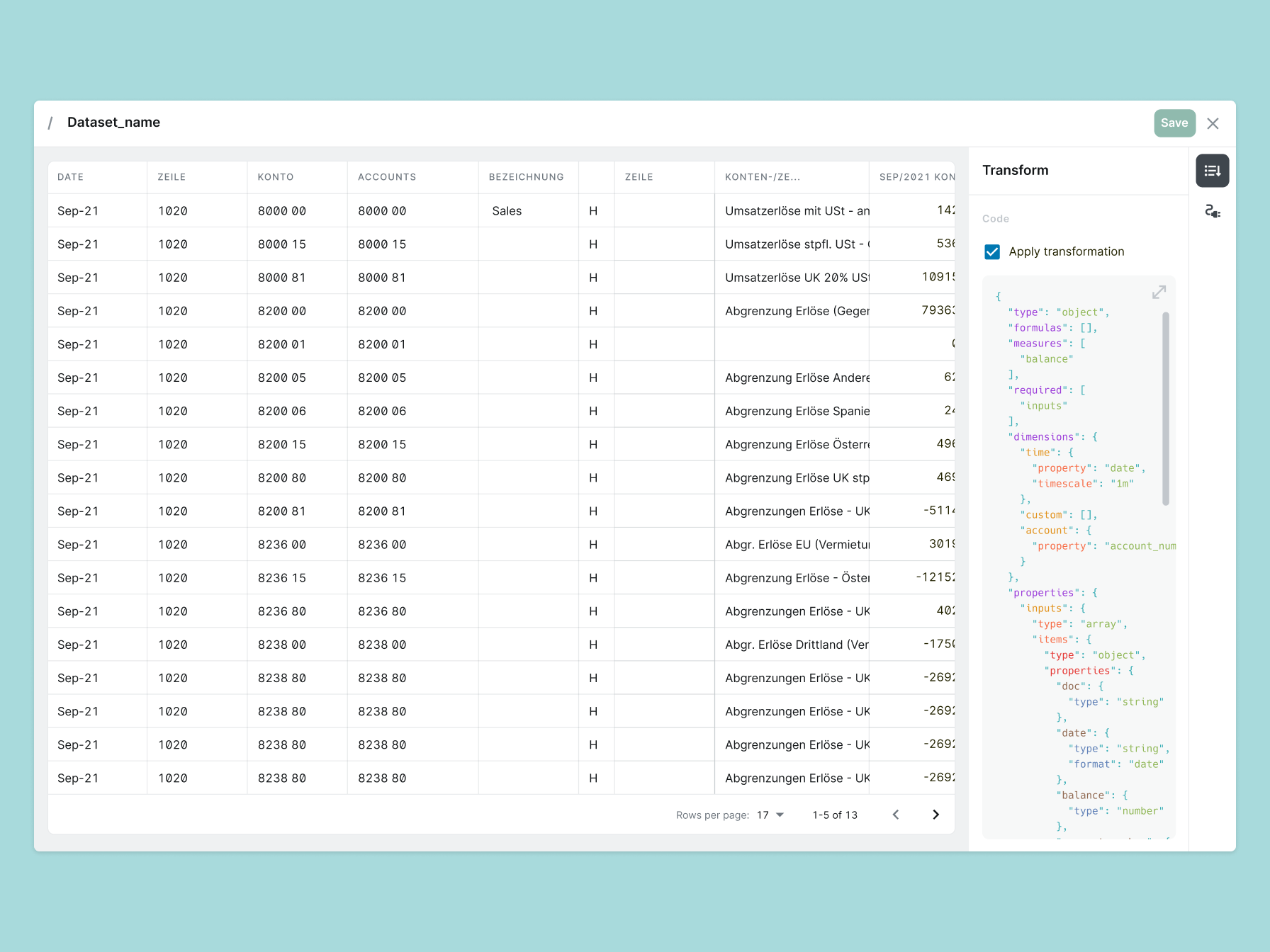
The system was already in use and we couldn't replace it in one step without risking existing customer setups, so no clean redesign.
SQL was the obvious candidate technically, and engineers knew it well. My instinct was against it. Our users had already built up fluency with the formula syntax from the modeling layer. Adding a second language would have split the experience.
We aimed to extend that vocabulary into the datasets layer instead, but migrations, technical dependencies, and the risk of breaking existing customer setups meant we had to move in small steps. When the formula approach wasn't ready, we fell back to SQL. That was deliberate, the goal was always one consistent language across the product.
The other major constraint was the language the interface used. The user tests made clear that FP&A teams didn't think in data types and schema objects. They thought in dimensions, mappings, and column formats. Translating the underlying technical model into that vocabulary, without changing what the system actually did, was one of the harder design problems in this work.
We also had to be deliberate about what we constrained. Some flexibility was intentionally removed in early iterations to prevent invalid configurations and reduce the risk of breaking downstream models. That was a tradeoff worth making: a slightly less powerful system that users could actually operate safely was more valuable than a fully flexible one they couldn't trust.
Solution
Introducing a usable layer on top of a flexible system
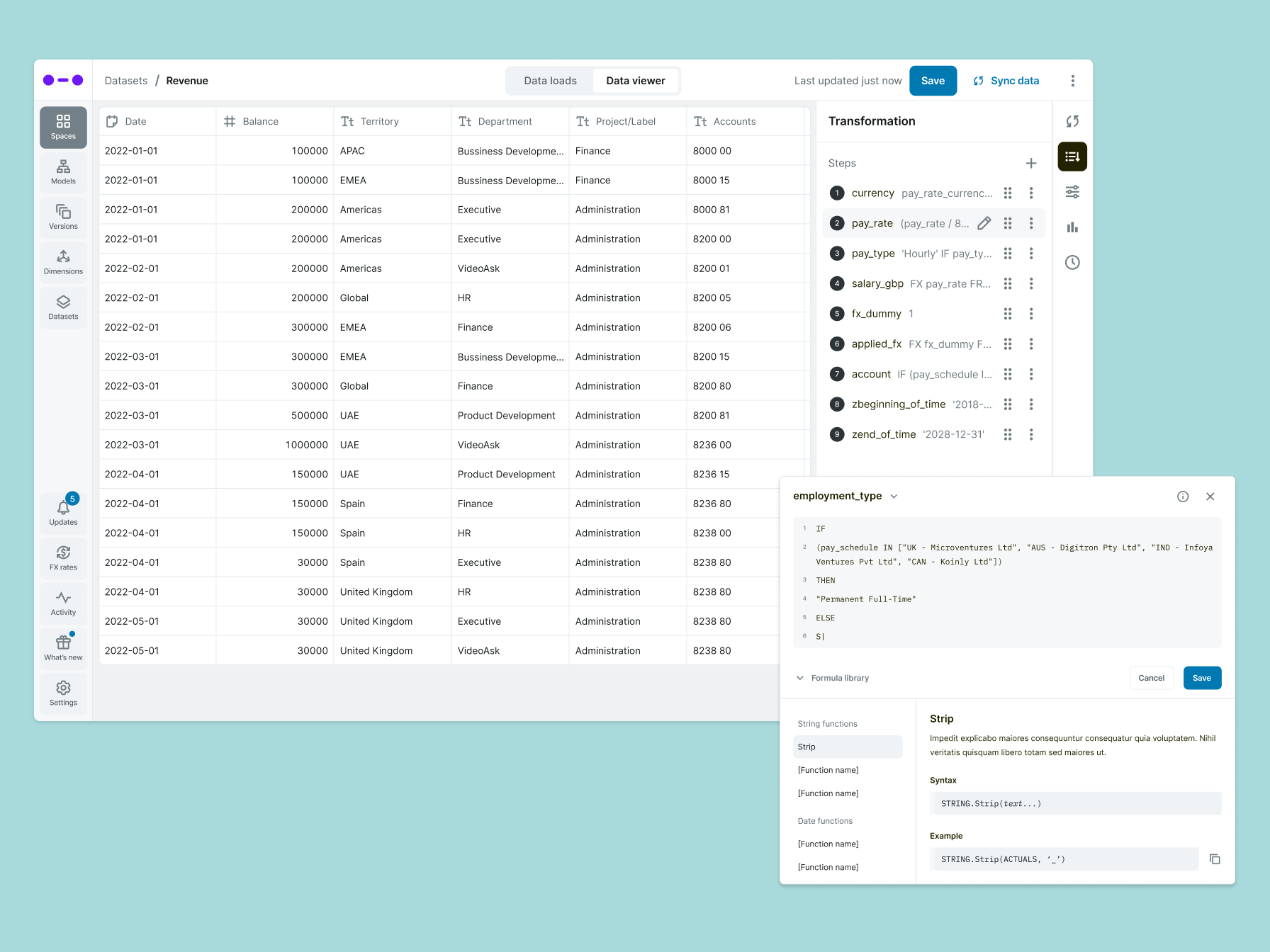
The core change was introducing an abstraction layer between users and the underlying data model, so finance teams could configure datasets in their own language rather than the system's.
The column builder was the most visible part of that shift. Users could select a column, define what it represented, reference other fields, and see immediately whether the configuration was valid. The system enforced constraints to prevent invalid states and caught errors before they could propagate to downstream models. That guardrail mattered as much as the interface itself. Finance teams were configuring data that other parts of the product depended on, and a silent error in a dataset could break a model hours later.
The work also made the connection between datasets and modeling more explicit. The two had evolved separately, with different vocabularies and interaction patterns. Bringing them closer together, even incrementally, made the product more coherent and reduced the mental overhead of switching between the two.
Not everything was fully shipped within the time I owned this squad. The formula-based transformation layer was the long-term direction but remained in progress. When I moved to the engine squad after about eighteen months, the foundation was in place but the vision wasn't complete. The modeling syntax project I worked on after that move was part of the same thread: getting the language consistent across the product so the datasets layer could eventually build on top of it properly.
Example
Creating a calculated column
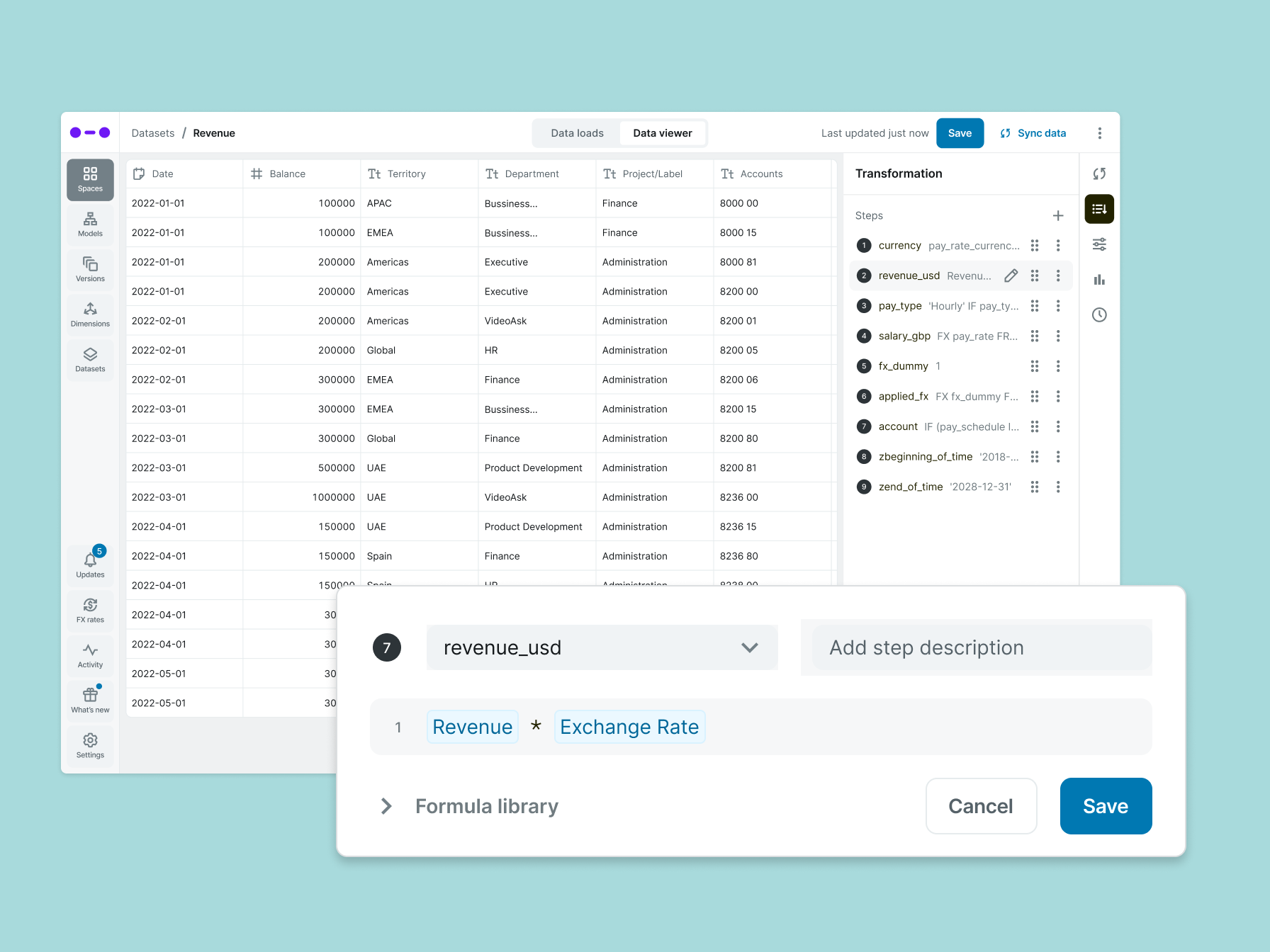
A typical transformation, converting revenue to a single currency, shows how much the experience changed.
Teams edited JSON directly. Creating a calculated column meant writing a configuration object by hand:
{
"column": "revenue_usd",
"formula": "revenue * exchange_rate",
"type": "number"
}To do this correctly, users needed to understand how the dataset was structured, the exact syntax for transformations, and where in the configuration this should be defined. There was no guidance in the product and no validation beyond whether the JSON was technically valid. If something was wrong, it often failed silently or produced incorrect data downstream. In practice, most finance teams didn't do this themselves. They relied on the implementation team to write or review these transformations.
After the redesign, the same column gets created through a structured interface. Users can select an existing column, define a transformation using a formula-like input, reference other fields, and immediately see whether the configuration is valid. The interaction is closer to how they already work in spreadsheets, and the system only allows valid operations.
The tradeoff is the system is less flexible than editing JSON directly, especially for edge cases, and some advanced transformations required additional steps or weren't supported in early versions. But for the majority of use cases the change was real: errors were caught earlier, teams could make changes without relying on implementation support, and the configuration became something a finance team member could reason about on their own.
Outcomes
Finance teams that had relied on the implementation team for every integration change started handling most of it themselves.
By the end of my time on the squad, the impl team's read was that they were spending roughly half the time on standard dataset configuration compared to before, which freed them for edge cases and complex setups. That shift was visible internally before it appeared anywhere else. Routine work had stopped requiring expert mediation.
Customer support saw the same thing. Dataset configuration requests dropped noticeably in the two quarters after rollout, according to CS triage. The consistent feedback: teams felt more in control of their data than before.
On the product side, the clearest marker was that autonomy stopped blocking onboarding. Customers were getting to a working dataset configuration in their first session, where previously that had usually taken follow-up sessions with implementation. They could iterate from there instead of waiting on someone else.
The formula-based transformation layer was still in progress when I moved to the engine squad. But the foundation was solid enough that the work could continue without me.